High-performance embedded module and system designers must understand the technical considerations required to fully realize the true benefits of 100G technology.
In the context of 100 Gbps technology for the VPX ecosystem, simply stating that a module or system supports 100 Gbps is, by itself, insufficient for ensuring the full benefits of the claim. If a vendor’s datasheet for a VPX plug-in card (PIC) or system states 100 Gbps support but is unable to fully utilize the potential of this high-speed connectivity, that claim – while while perhaps technically accurate – overstates the product’s ability to deliver the full benefits that 100 Gbps promises.
At face value, a vendor’s claim to support 100 Gbps technology implies 2.5 times faster <something> compared to 40 Gbps technology, and 10 times faster <something> compared to 10 Gbps technology. In an ideal world, the mathematical relationship between 100 and 40 will result in 2.5 times better performance. Likewise, 100 to 10 should yield a 10-time performance increase. Unfortunately, the real world does not work like that. A 16-core laptop processor does not allow a person to work 4 times faster when editing documents compared to their previous 4-core laptop.
Applications matter most
What that faster <something> is, as referred to above, will depend on what an application is trying to do. When referring to a specific Ethernet interconnect technology, the <something> might be, for example, data-carrying speed. But data-carrying speed does not translate directly into what the new higher-speed technology truly offers the end user. We could substitute the term “performance” for <something>, but again, performance is meaningless without context to its application and end purpose.
In the context of embedded computing for the defense and aerospace industry, the never-satisfied quest for higher performance tends to focus on three main areas of improvement:
- Faster time to solution: This means answers are derived faster. For example, if a targeting system can pinpoint and identify a target quicker, it may be able to implement countermeasures quicker. And in an environment where seconds or even milliseconds matter and lives are at stake, faster time to solution has significant and measurable benefits.
- Higher-fidelity information: In imaging systems such as radar and visual/camera systems, higher fidelity may mean higher resolution (such as 4K or 8K images instead of HD), or it may mean real-time motion video (such as 120 fps for smooth lower-latency real-time motion, instead of 15 fps). Enhanced fidelity enables personnel or automated vision systems to see farther with more clarity, which ultimately leads to earlier and more informed decision-making.
- Higher levels of integration: In today’s connected battlespace, information sharing and data integration are some of the most important pillars of growth. Within a platform and between platforms, data integration allows a diverse range of sensors and processing systems to share situational information, coordinate tactical actions, and achieve more desirable outcomes. In the context of the connected battlefield, information integration is paramount for mission success.
For each of these three areas of potential system improvement, an Ethernet connection forms only part of the overall system operation, so a faster Ethernet connection can only provide part of the overall improvement equation. For sensor processing systems, faster sensor connections may bring more sensor data to the sensor processor, but that does not ensure the sensor processor can fully process all the captured data. While the information highway may be able to carry more information traffic for interconnected systems, it does not ensure that connected systems can use all of the potential flood of available information.
Figure 1 is a simplified example showing where Ethernet can be used both to connect sensors to processing systems and to interconnect multiple processing systems together to share information.
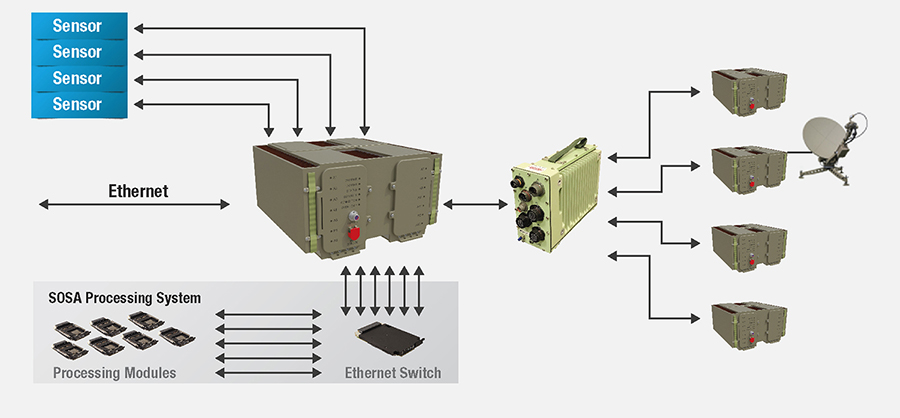
[Figure 1 ǀ System of systems showing Ethernet connections.]
While all these Ethernet connections are candidates for increased 100 Gbps data rates, we must consider the characteristics of the data each of these connections carries and how any increase in Ethernet speed can benefit a particular application, a subsystem, or the entire system of systems.
SOSA understands TCP vs. UDP
The Open Group Sensor Open Systems Architecture (SOSA) has gained considerable industry acceptance as the go-to for system architectures. Within the SOSA Technical Standard there are observations and recommendations reinforcing the notion that TCP [transmission control protocol] incurs considerably more overhead than UDP [user datagram protocol] for high-bandwidth data-moving applications. The SOSA Technical Standard defines Support Level Ethernet 1 (SLE1) as optimized for control applications and mandates a full TCP Ethernet stack, whereas Support Level Ethernet 2 (SLE2) is optimized for high-bandwidth data applications and recommends using the UDP protocol and jumbo packets. It also observes that SLE2 (using UDP) may be required for low-latency message use.
Takeaway: Real-time sensor data is best suited for UDP protocol for reduced latency, while control functions require TCP for reliability.
Specialized processors, such as FPGAs, and derivatives, such as AMD’s MPSoC and adaptive SoC devices, excel at streaming and processing the extremely high-throughput signals generated by modern radar, video, signals intelligence, and similar sensors. By tightly coupling programmable logic (PL) to one or more Ethernet interfaces, it is possible to operate at close to theoretical throughput limits if so desired. However, complex protocols, including TCP/IP, are not readily or efficiently implemented in PL logic, which is a major reason why SOSA’s UDP-based SLE2 is preferred for streaming.
Data-buffer management and RDMA
Consider an application example where we want to send a large amount of data across the network. In this example, we’ll move 100 MB of data across a 100 Gbps Ethernet connection. Using quick math, one might expect to transfer this data in 8 milliseconds (ms). How realistic is this?
First, we cannot send the full 100 MB of data in a single Ethernet packet. Ethernet packets range in size from 46 up to 1,500 payload bytes for standard packets or 9,000 payload bytes if jumbo packets are configured. Our 100 MB of data will be broken down into 68,267 standard packets or 11,378 jumbo packets, each of which must be individually packaged and sent. The network stack will take several sequential steps to package the data and eventually pass the data to the Ethernet kernel driver, which will send it packet-by-packet to the Ethernet NIC [network interface controller] for transmission. The bottom four layers of the OSI stack alone typically perform at least two data-buffer copy operations, each of which will take time and consume CPU cycles. Overall, between three and six data-buffer copy operations will be performed, with some implementations being better than others. The final step of transferring the packet from the kernel driver to the Ethernet NIC is often performed using DMA operations, which simply frees up CPU cycles from the task.
In a TCP/IP network operating over an unreliable Ethernet link, each layer serves a particular purpose and should not be bypassed. However, in a well-controlled reliable network, bypassing some of these layers to eliminate unnecessary overhead and increase efficiency may be desirable. Remote DMA (RDMA) is a technology that does this; it bypasses several of the OSI layers and performs the DMA transfer directly between the application data structures and the Ethernet NIC device. RDMA is often referred to as having “zero-copy” data transfers. Figure 2 illustrates the data-handling operations for a standard TCP/IP network stack on the left and an RDMA network stack on the right.
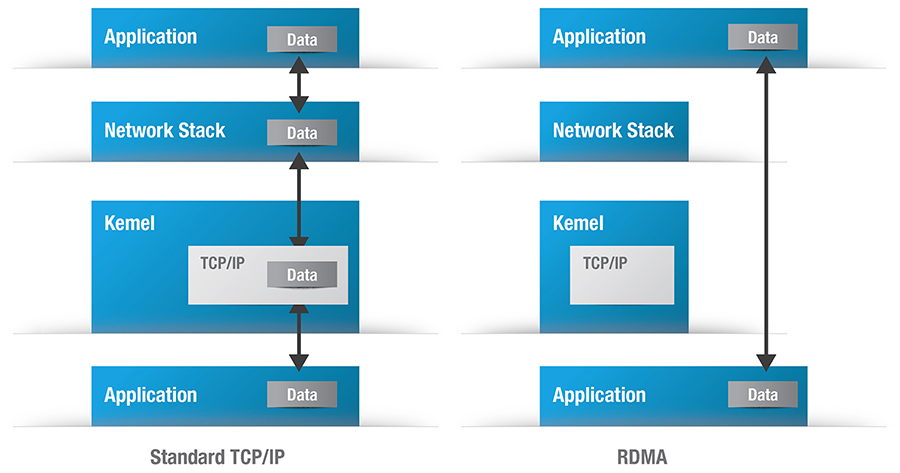
[Figure 2 ǀ Simplified view of data passing in a Linux operating system for TCP/IP vs. RDMA operations.]
With its reduced overhead for data copying and packet processing, the main benefits of RDMA network stacks are their ability to free up valuable CPU cycles for other tasks while reducing latency and improving overall network performance. RDMA is best suited for applications that send large chunks of data from node to node in reliable networks. For this reason, it has gained mainstream acceptance in data centers and storage area networks. For applications that need to process the content of packets on a more granular level or when operating in a potentially unreliable network, non-RDMA TCP/IP stacks remain the more appropriate choice.
It is worth noting that RDMA operations take overhead time to set up. For large data transfers, this overhead is a small price to pay for the time savings spread across the entire large data transfer. However, for small messages, the overhead time needed to set up RDMA operations can easily exceed the non-RDMA data buffer processing times. RDMA operations are thus rarely used for small latency-sensitive messages.




Takeaway: Choosing the right network protocol can have a significant effect on message latency and CPU utilization.
Processing 100 Gbps streams of Big Data
Very few applications generate or consume 100 Gbps of data. Mathematically, 100 Gbps equates to roughly 10 GBytes (GB) of data per second. In context, a modern processor with a 64-bit DDR4 memory subsystem operating at 2,400 MT/sec can only transfer data to or from its high-speed DRAM memory at a theoretical maximum of 19 Gbps, meaning just reading or writing a 100 Gbps data stream will consume over half of a 64-bit modern memory channel’s bandwidth under ideal conditions. Under real-world conditions, the 10 GBps data stream will consume closer to 60% to 70% of the available memory bandwidth. So how can a modern processor provide or consume data at these incredibly high rates?
Memory architectures matter
Many modern processors have more than one DRAM memory channel. In the Intel processor family, the mainstream “Core” processor families, such as Core i7 or Xeon E/W/H families, have two independent 64-bit memory channels. This means they can provide double the memory throughput compared to a single memory channel processor and simultaneously process two independent memory access streams. For a 2-channel DDR4 @ 2,400 MT/s memory subsystem, supporting a fully utilized 100 Gbps data stream will consume less than 35% of the real-world memory bandwidth. For newer dual-channel DDR5 @ 4,800 MT/s processors such as the 13th-gen Raptor Lake H family, a sustained 100 Gbps data stream will consume less than 18% of the memory bandwidth.
The Intel Xeon D family of processors are server-class devices with more processing cores and additional memory channels. The Ice Lake D processor family offers up to four memory channels to support up to 20 processor cores. Even a processor implementation with three memory channels will provide 50% more memory bandwidth compared to a same-speed 2-channel system.
Processing cores matter
Not all applications can use the RDMA network protocol, and many must support standard TCP/IP traffic streams. While most modern Ethernet NICs will perform some packet processing tasks, such as cyclic redundancy check (CRC) calculations, in hardware, the TCP/IP software stack will still be traversed with considerable network traffic and will be tasked with processing this data, packet by packet, at network line rates. If the CPU cannot keep up with the torrent of packets, packets will be discarded, and recovery mechanisms will adversely affect performance.
A 100 Gbps network stream is transmitted as 68,267 separate 1,500-byte packets, all within one second. That means each packet must be processed in under 14 µS. If the packet processing stack takes (for arguments’ sake) 7 µS to process the packet, the network stream will consume 50% of the processor’s available bandwidth. This assumes there is only one CPU core doing the work.
A typical Linux operating system, even when seemingly idle, has hundreds of separate processes running that perform tasks ranging from basic housekeeping to managing complex real-time network stacks. Modern processors are multicore devices that can execute multiple threads or tasks in parallel. The more processing cores a CPU has, the more parallel threads it can perform. The Linux TCP/IP stack supports multicore processors, allowing most modern multicore processors to spread network stack processing across multiple cores and threads to support full-bandwidth 100 Gbps TCP/IP network traffic while simultaneously providing significant CPU cycles to other tasks and application needs.
By contrast, FPGA-based processing systems are highly parallel in nature and operate optimally with streaming data flows. As an example, a 100 Gbps or 10 Gbps data stream could represent 16-bit wideband RF signals at 5 gigasamples per second (GSPS), capturing in excess of 2.2 GHz RF bandwidth. A single conventional scalar processor would be highly challenged to do useful processing at this high rate, so implementing a system solution where an FPGA distributes signal packets across multiple processors is one viable approach.
Using 100G for low-latency messaging
The previous example explored a processing architecture to support high-throughput 100 Gbps network traffic. But what if we want to optimize for the lowest possible message latency?
An Ethernet hardware switch typically adds a fixed ~1 µS to a packet’s transit time from sender to receiver. Electrical or optical transmission times are orders of magnitude smaller than this and are small enough to be ignored. The largest offender in a TCP/IP packet’s end-to-end latency journey is usually the network software stack processing time, along with the time a packet spends in buffers and queues waiting to be processed. As most of the TCP/IP packet processing time is CPU-bound, reducing the TCP/IP network stack processing time will directly reduce message latency.
The Intel Ice Lake Xeon D processor is a modern multicore processor with up to 20 hyperthreading cores. It excels with applications that scale well with parallelism and can use all 20 cores and 40 threads. It also excels for large data-management applications, with many cores/threads available to support complex data processing tasks. These same processing cores must also manage network packet processing.
It’s important to consider the processor’s core clock speed for low-latency messages. The Ice Lake Xeon D processor operates with a core clock of 2.0 GHz. In contrast, Intel’s Xeon E/W/H series processors provide fewer cores operating at higher clock speeds. For example, the 9th-gen Coffee Lake Xeon E operates at 2.8 GHz, providing approximately 40% higher per-thread performance, and in the context of faster network software processing times will yield lower overall Ethernet latency results compared to the Ice Lake D processor.
Lastly, we must mention an important system-level characteristic of Intel processors: Intel processors have safety mechanisms to ensure the processor does not overheat, called “throttling.” If the processor becomes too hot (thermal throttling) or consumes too much power (TDP throttling), it will self-throttle and reduce its clock speeds and performance to reduce power consumption and generate less heat. While a 100 Gbps network connection maintains the same bit-rate speed across the physical medium, if the packet-processing processors at an endpoint are throttled, its performance may be reduced to the point where it can no longer process packets quickly enough to sustain a 100 Gbps network data throughput.
With today’s high-power processing modules, standard thermal-cooling solutions such as conduction cooling may not be sufficient to keep processors operating at their full performance potential. Higher-performance cooling solutions will yield more favorable results at high operating temperatures.
Going forward with 100G
Data processing and sharing for defense and aerospace applications is rapidly becoming more complex. To deliver the faster processing and massive information-sharing benefits that modern systems require, system designers are turning to 100G technologies. But to fully realize all the benefits that 100G systems can offer, system architectures must also adapt in order to support the faster data and reduced latencies that 100G technologies promise. It is not sufficient to just support 100G-capable Ethernet ports.
As these new high-speed interconnect technologies are adopted, they will move from hype and promise to mainstream and proven, delivering a massive performance boost to the connected battlefield, where critical decisions are made at the speed of relevance.
Curtiss-Wright’s Fabric100 family delivers a complete end-to-end solution for architecting 100Gbit SOSA aligned rugged systems. Fabric100 brings 100Gbit Ethernet and high-performance PCIe Gen4 interconnect speeds to tomorrow’s new generation of rugged deployable computing architectures. It is not enough to simply provide 100G connections between a system’s modules yet fail to support the ability to process all this data within the modules themselves.
Recognizing that, Curtiss-Wright’s Fabric100 board architectures are designed to deliver full 100G performance through the entire processing chain, eliminating data bottlenecks that might otherwise compromise system performance.
Aaron Frank is Senior Product Manager at Curtiss-Wright Defense Solutions.
Curtiss-Wright Defense Solutions https://www.curtisswrightds.com/